MPS Generators
In this article, I will give an introduction to MPS Generators. These are used to transform program code written in one computer language to code written in another computer language, usually with a lower abstraction level. The first paragraph explains MPS generators, and the second explains one of the transformation statements.
Introduction MPS Generators
The MPS Generator aspect deals with transforming code in a domain specific language (DSL) to code in a lower level of abstraction language. This language can then be interpreted or compiled into executable code, or transformed into code for other purposes, such as presentation. Examples:
-
Chemical reactions specified with a language for that gets transformed to Java code.
-
An inventory specification specified with a DSL gets transformed to HTML and CSS files for presentation on the web.
First, it is important to understand that in MPS transformations there are 3 different artifacts involved:
-
The input model: the DSL model to be transformed
-
The output model: the lower level of abstraction model
-
Code in the form of text files.
To start with, in MPS terminology, a node is an instance of a concept, the same way an object is an instance of a class. The input model consists of nodes of concepts of the DSL language, structured in a tree of nodes. The output model likewise consists of nodes of concepts of a lower level of abstraction language, such as a Java or C#, also structured in a tree of nodes. The code in the form of text files are a textual representation of the output model, used to compile the text files to executable code.
The transformation takes place in two steps:
-
The input model gets transformed to the output model, using a number of MPS generator transformation statements.
-
The output model get transformed to text files by the text generator.
In the case of MPS, the output model consists of nodes of concepts of a Java like MPS language, called Base Language. The build-in functionality of MPS takes care of transforming these nodes to Java code in the form of text.
In the subsequent paragraphs, several transformation statements will be explained.
Loop macro
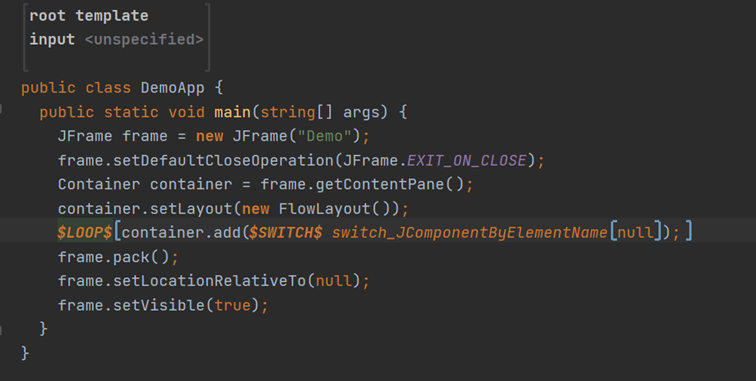
With a Loop macro, a collection of input nodes is run through.
For each iteration of the loop, the output language code that is within the $LOOP$ brackets is repeated.
The output language code can then be modified with other macros, such as a switch macro or a property macro.
These macros are offered the input node of the iteration.
They futher specify the generated code for each iteration.
Figure 1. Example of Loop macro with template switch macro
If you open the settings of the Loop macro with the inspector (set the cursor in $LOOP$, and open the inspector with ALT+2), you can enter a statement that determines the collection to be iterated.
In the example below, the Loop macro iterates through all the XML document root elements of the input model:
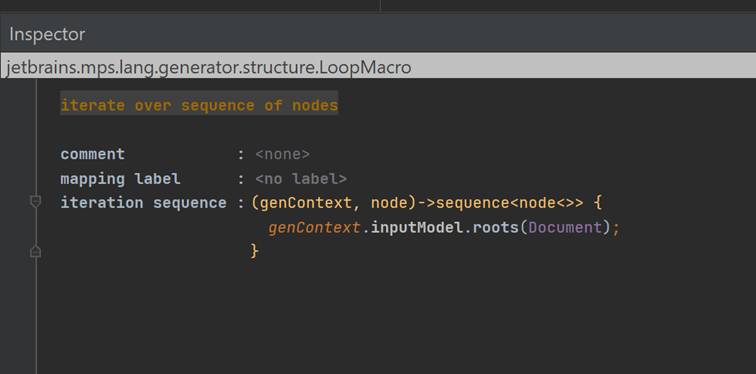
Figure 2. Use inspector to set iteration sequence
The switch macro is offered a document input node per iteration (and switches depending on the name of the root element of the XML document).
Another example:
A Loop macro is used to repeat an output language template (e.g. containing a string constant) for each item of a collection.
The constant itself can then be changed with a property macro in a property of an item node.
See video: https://www.youtube.com/watch?v=i-65_1E3vuI
It also explains that node.index refers to the index of the current iteration.